

Research - A Formal Threshold Model for B-Tree Performance Degradation Under Random Primary Keys in OLTP Systems
We prove that this degradation is a physical limitation of B-Tree mechanics under random insertion, compounded by Write Amplification Factor (WAF) penalties, rather than a hardware or traffic-scaling


The adoption of UUIDv4 as a primary key in OLTP databases has become a widespread default, driven by ORM convenience and distributed system requirements.
This paper demonstrates that UUIDv4 primary keys guarantee severe, predictable performance degradation as table size grows. We introduce the Buffer Saturation Ratio (BSR) and derive a closed-form threshold (N*) that predicts exactly when write latency will spike.
We prove that this degradation is a physical limitation of B-Tree mechanics under random insertion, compounded by Write Amplification Factor (WAF) penalties, rather than a hardware or traffic-scaling failure.
The Anatomy of a Deferred Crisis
Modern frameworks make it trivial to assign a random, 128-bit string as a primary key. Distributed ID generation solves immediate engineering headaches. It prevents sequence contention. It hides entity counts from users.
But it introduces a delayed tax on your storage layer.
Engineers rarely observe the cost of UUIDv4 during the first year of a project. Databases aggressively cache active indexes in RAM. As long as the primary key index fits entirely within the database buffer pool, random inserts perform acceptably.
The crisis arrives silently. The index quietly outgrows the allocated memory. The database begins reading cold pages from the physical disk to complete routine inserts. Write latency jumps by two orders of magnitude. The typical engineering response, upgrading the instance class which fails to resolve the underlying physics.
B-Tree Mechanics and the Fill Factor Penalty
Relational databases use B-Tree variants to store indexes. Sequential keys, such as BigInt sequences or UUIDv7, append new records to the rightmost edge of the tree. The database keeps that single, active leaf node hot in memory.
UUIDv4 values possess zero temporal locality. Every insert targets a random location in the B-Tree.
When you insert a record into a random leaf node that is already full, the database executes a page split. It allocates a new page (16KB in MySQL InnoDB, 8KB in PostgreSQL), transfers half the records, and updates the parent nodes.
Sequential inserts achieve a high index fill factor (f ≈ 0.90 to 0.94). Random UUIDv4 inserts guarantee continuous page splits, driving the equilibrium fill factor down to approximately 0.50. You are permanently storing half-empty pages. Your index requires twice the RAM just to exist.
The Buffer Saturation Ratio (BSR)
To predict performance failure, we must track the relationship between index size and available memory. We define the Buffer Saturation Ratio (BSR)
Where Bpool is the configured memory for caching (InnoDB Buffer Pool or PostgreSQL shared_buffers), and Isize is the total size of the primary key index.
When BSR ≥ 1.0, the entire index resides in memory. Writes are fast.
When BSR < 1.0 , the index exceeds available RAM.
At BSR < 1.0, every random insert carries a cache miss probability (Pmiss)
When a cache miss occurs, the database evicts a page to load the target leaf node from disk. Because UUIDv4 targets pages uniformly, the newly loaded page is highly unlikely to be reused before it is evicted again. This creates LRU eviction thrashing.
Your expected insert latency (Linsert) becomes completely dominated by disk I/O
Deriving the Threshold Row Count (N*)
We can calculate the exact row count where a database will fall off the performance cliff. First, we model the projected index size
Where
N = Number of rows
Ksize= Key size in bytes (16 for binary UUID, 36 for char UUID, 8 for BigInt)
Poverhead = Pointer overhead (roughly 8 bytes)
f = Fill factor (0.50 for UUIDv4, 0.94 for BigInt)
To find the threshold row count (N*), we set Isize equal to Bpool (BSR = 1.0) and solve for N
This equation allows architects to project the exact lifespan of a database schema configuration.
Write Amplification Factor (WAF)
Random inserts punish the storage layer beyond just cache misses. They generate massive Write Amplification Factor (WAF) in the Write-Ahead Log (WAL).
The write amplification for a UUIDv4 index follows a logarithmic curve
Where m is the B-Tree order (roughly 80 for InnoDB at 16KB pages with 200-byte rows), N is total rows, and M is the number of rows that fit in the buffer pool.
Your total write amplification multiplies by your secondary indexes (k)
MySQL InnoDB uses clustered indexes. The massive, random primary key is duplicated into the leaf nodes of every secondary index. PostgreSQL uses heap tables, bypassing clustered index bloat, but secondary indexes still suffer the brutal page split penalty and identical WAF multipliers.
Case study
One of my client ran a package scan event log using a char(36) UUIDv4 primary key on a 16 GB RDS instance equipped with a 12 GB buffer pool.
During the first year, at 50 million rows, performance remained nominal. Their BSR sat at 8.0. The buffer pool easily absorbed the random writes.
The table eventually reached 500 million rows. The char(36) key, combined with the 0.50 fill factor, swelled the index size to roughly 15 GB.
Their BSR dropped to 0.80. Write latency instantly climbed from 2 ms to 200 ms. CPU utilization on the RDS instance pinned at 90 percent, entirely consumed by managing LRU evictions.
They upgraded the RDS instance class twice. Neither upgrade resolved the latency. Each vertical scaling event raised CPU, RAM, and the buffer pool proportionally, but the BSR remained strictly below 1.0. The index remained larger than the pool.
Hardware scaling cannot outrun mathematical thresholds. The only viable solution was migrating the primary key to a sequential format.
The N* Decision Matrix
Applying the N* formula to standard infrastructure configurations reveals the severe capacity penalty of UUIDv4 strings
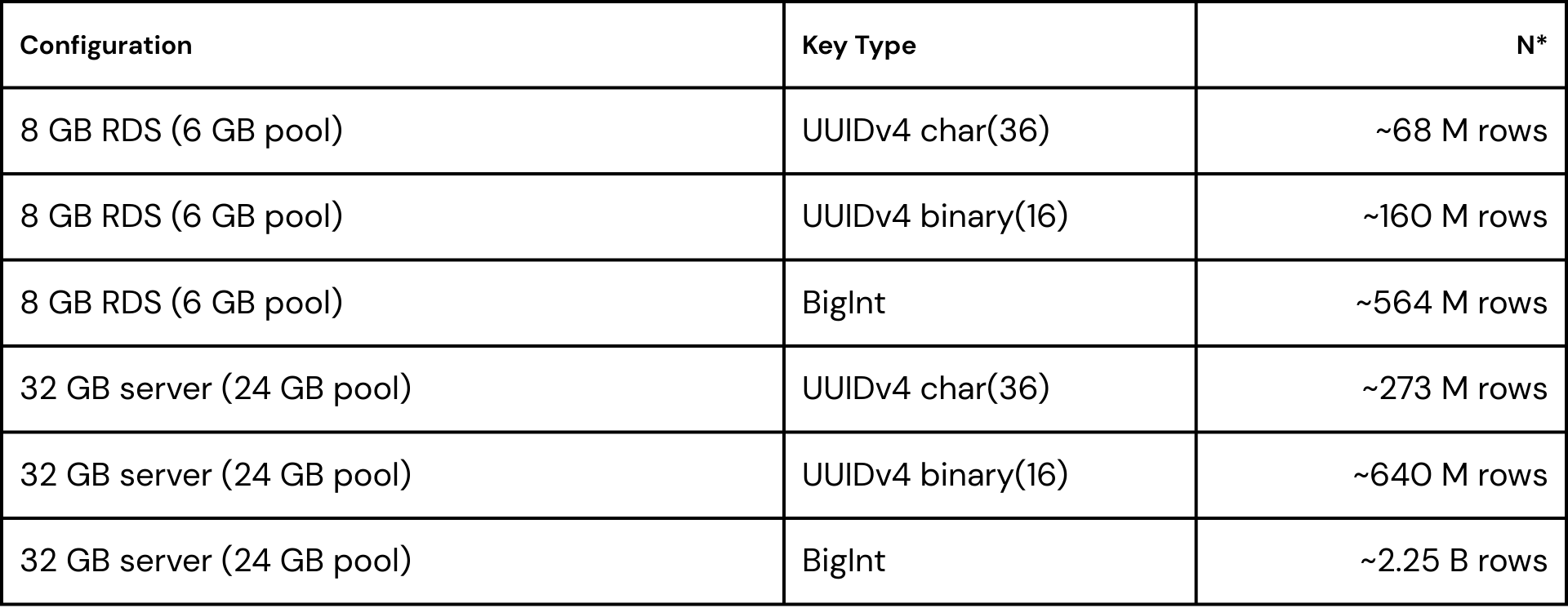
A 32 GB server running a char(36) UUIDv4 index chokes at 273 million rows. The exact same hardware running a BigInt handles 2.25 billion rows. You are paying a 400 percent RAM tax for a framework default.
Conclusion
UUIDv4 primary keys constitute a systemic architectural flaw in high-throughput OLTP databases. They actively defeat database caching mechanisms and maximize physical disk I/O.
Engineers must stop treating database performance degradation as a generic symptom of traffic scaling. Use the N* threshold formula to project your schema’s structural limits before executing a CREATE TABLE statement.
If distributed ID generation is a hard requirement, adopt temporally sequential identifiers like UUIDv7 or ULID. Align your data structures with the physical constraints of B-Tree mechanics.
Read the paper here
https://zenodo.org/records/19034540